AI Data Quality pour Alteryx : notre bibliothèque d'outils pour fiabiliser vos données à l’ère de l’IA — et pourquoi nous l’avons rendue gratuite
1. Le mur de la Data Quality : ce que dit vraiment la data
Selon l’étude conjointe MIT Technology Review Insights × Snowflake (2024), menée auprès de plus de 275 dirigeants d’entreprises internationales, 78 % des entreprises ne sont pas encore entièrement prêtes pour l’IA générative. Le rapport identifie trois blocages prioritaires : la gouvernance des données, la sécurité des données, et la qualité des données.
Cette statistique n’est pas surprenante. Ce qui l’est plus, c’est ce qu’elle recouvre concrètement. Dans notre pratique quotidienne chez les grandes banques françaises et européennes, les problèmes de qualité de données se déclinent en cinq familles récurrentes :
• Complétude défaillante : des champs obligatoires manquants dans 5 à 30 % des enregistrements — souvent silencieusement, sans alerte
• Incohérences de format : mêmes données codées différemment selon la source (dates, devises, codes pays, noms de tiers)
• Doublons non détectés : entre 2 et 15 % de doublons dans les référentiels clients / tiers
• Valeurs aberrantes non identifiées : outliers qui polluent les analyses statistiques et les modèles ML
• Documentation absente : datasets sans description, sans lineage, sans propriétaire clair
Un projet IA lancé sur ce type de socle est condamné à sous-performer, quelle que soit la qualité du modèle utilisé. C’est là que se joue le vrai combat : dans la fiabilisation en amont, pas dans l’ingénierie du modèle en aval.
Le “so what” pour votre organisation
Avant de lancer votre prochain projet IA, imposez à vos équipes un audit Data Quality de 5 jours sur les jeux de données critiques concernés. Vous découvrirez que 60 à 80 % de la valeur du projet dépend de cet audit — pas du choix de LLM ou de framework.
2. Notre parti pris : Alteryx comme colonne vertébrale de la Data Quality
Nous aurions pu construire une bibliothèque en Python autonome. Nous aurions pu la déployer sur Snowflake, Databricks, ou une plateforme cloud native. Nous avons choisi Alteryx. Voici pourquoi.
Alteryx est déjà présent dans les grandes banques. Chez plusieurs de nos clients (dont une banque universelle française où 700+ collaborateurs Finance utilisent Alteryx au quotidien), l’outil est devenu le socle analytique des équipes métier. Ajouter des capacités Data Quality dans Alteryx, plutôt qu’à côté, c’est rencontrer les utilisateurs là où ils sont — pas leur imposer un nouvel outil.
Alteryx est no-code. Un contrôleur de gestion, un risk manager ou un chargé de conformité peut utiliser nos add-ons sans écrire une ligne de Python. C’est un enjeu d’adoption : les meilleurs outils Data Quality ne servent à rien s’ils restent dans le placard des Data Engineers.
Alteryx est déjà intégré aux stacks bancaires. Connecteurs natifs vers SQL Server, Oracle, Snowflake, Databricks, SharePoint, Power BI, Tableau. Nos add-ons héritent de cet écosystème sans surcoût d’intégration.
Le “so what”
Vous avez déjà Alteryx dans votre organisation ? Utilisez-le comme colonne vertébrale de votre Data Quality. Vous n’en avez pas mais utilisez Excel/Power Query au quotidien ? La bascule vers Alteryx pour des workflows Data Quality industrialisés est un des meilleurs ROI que nous ayons observés — souvent moins de 6 mois pour rentabiliser les licences.

3. Deux familles d’outils, une philosophie unifiée
Notre bibliothèque combine deux logiques distinctes mais complémentaires.
D’un côté, des outils Data Quality classiques, déterministes. Ils appliquent des règles claires, produisent des résultats reproductibles, et fournissent un audit trail précis. Ils sont indispensables pour la conformité réglementaire — un reporting AnaCredit, FINREP/COREP ou Bâle IV n’accepte pas d’incertitude dans les contrôles.
De l’autre, des outils IA générative, non déterministes mais souples. Ils tirent parti des grands modèles de langage (Mistral, OpenAI, Claude, Gemini) pour traiter ce que les règles ne peuvent pas : synonymes, fautes d’orthographe, formats hétérogènes, textes libres.
La règle d’or que nous appliquons chez nos clients : commencer par le déterministe (rapide, auditable, économique), puis mobiliser l’IA générative uniquement là où elle apporte une valeur incrémentale — sans jamais compromettre la souveraineté ni la gouvernance.
Cette hiérarchisation évite deux pièges classiques : le tout-IA (coûteux, imprévisible, difficile à auditer) et le tout-règles (rigide, incapable de traiter les cas ambigus).

4. Un échantillon de nos outils AI Data Quality pour Alteryx
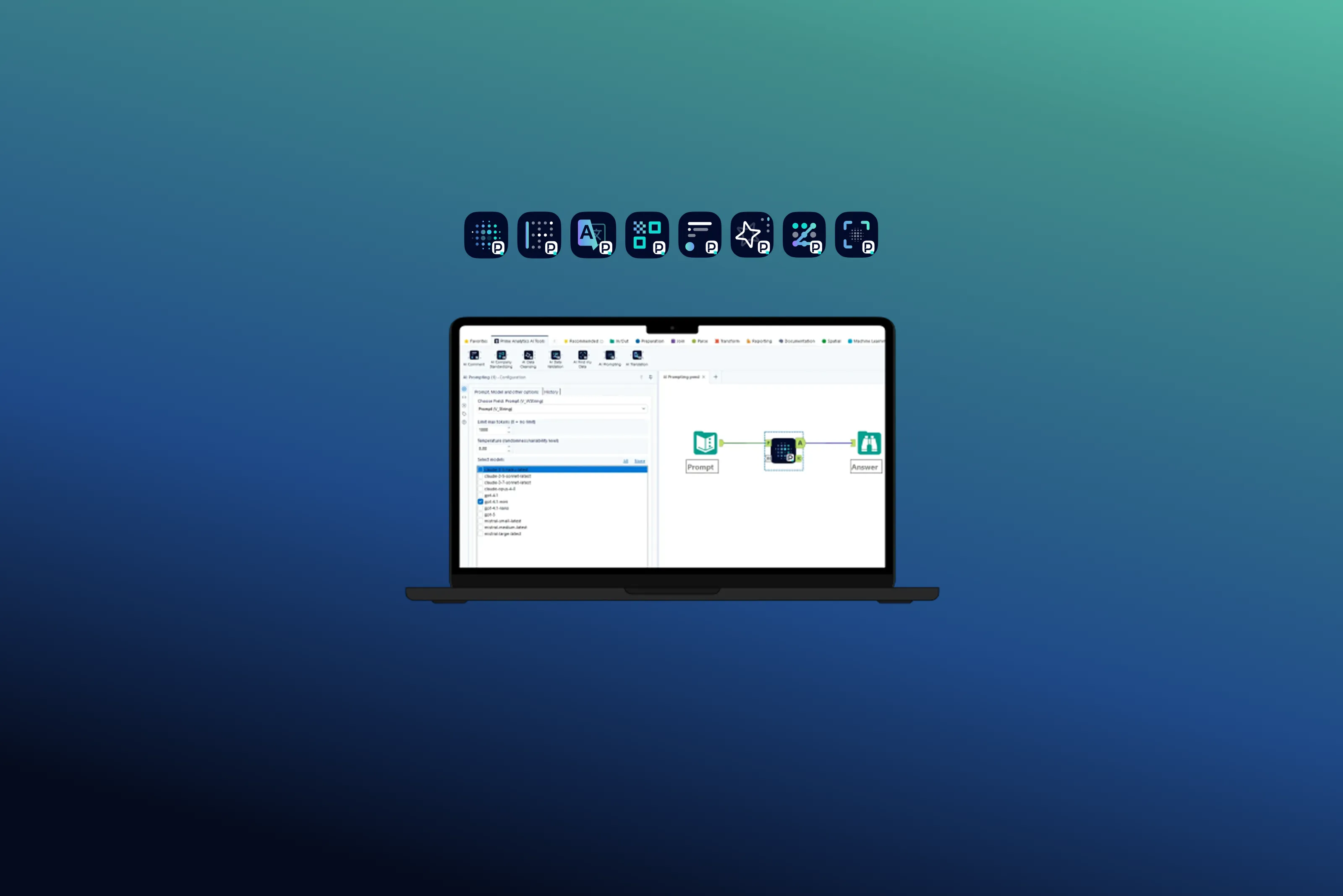
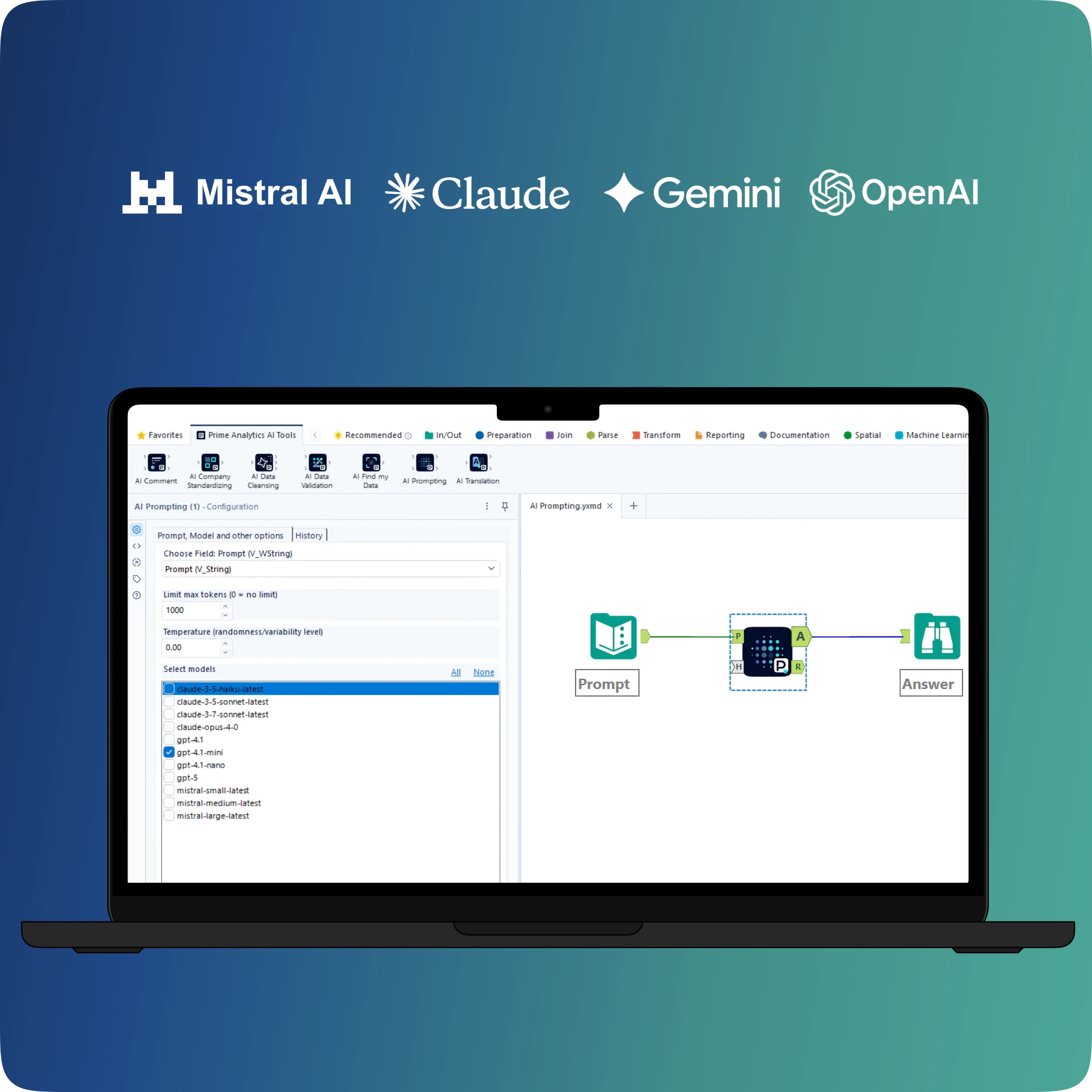
• AI Prompting — Le pont vers l’IA générative
Interroge un modèle LLM depuis Alteryx avec des credentials configurables. Compatible ChatGPT, Claude, Mistral, Gemini, modèles internes.
Capacités avancées : 1 modèle × N prompts (batch), N modèles × 1 prompt (comparaison), N modèles × N prompts (benchmark complet).
Piège à éviter : ne pas envoyer de données personnelles à un LLM externe sans avoir vérifié votre cadre RGPD / AI Act.
• AI Comment — L’enrichissement contextuel automatisé
Génère automatiquement un commentaire contextuel pour chaque ligne d’un dataset. Ton configurable (formel, concis, détaillé). Base de connaissances optionnelle.
Cas d’usage : synthèses commerciales, commentaires de contrôle de gestion, annotations documentaires.
Piège à éviter : ne jamais mettre en production sans validation humaine.
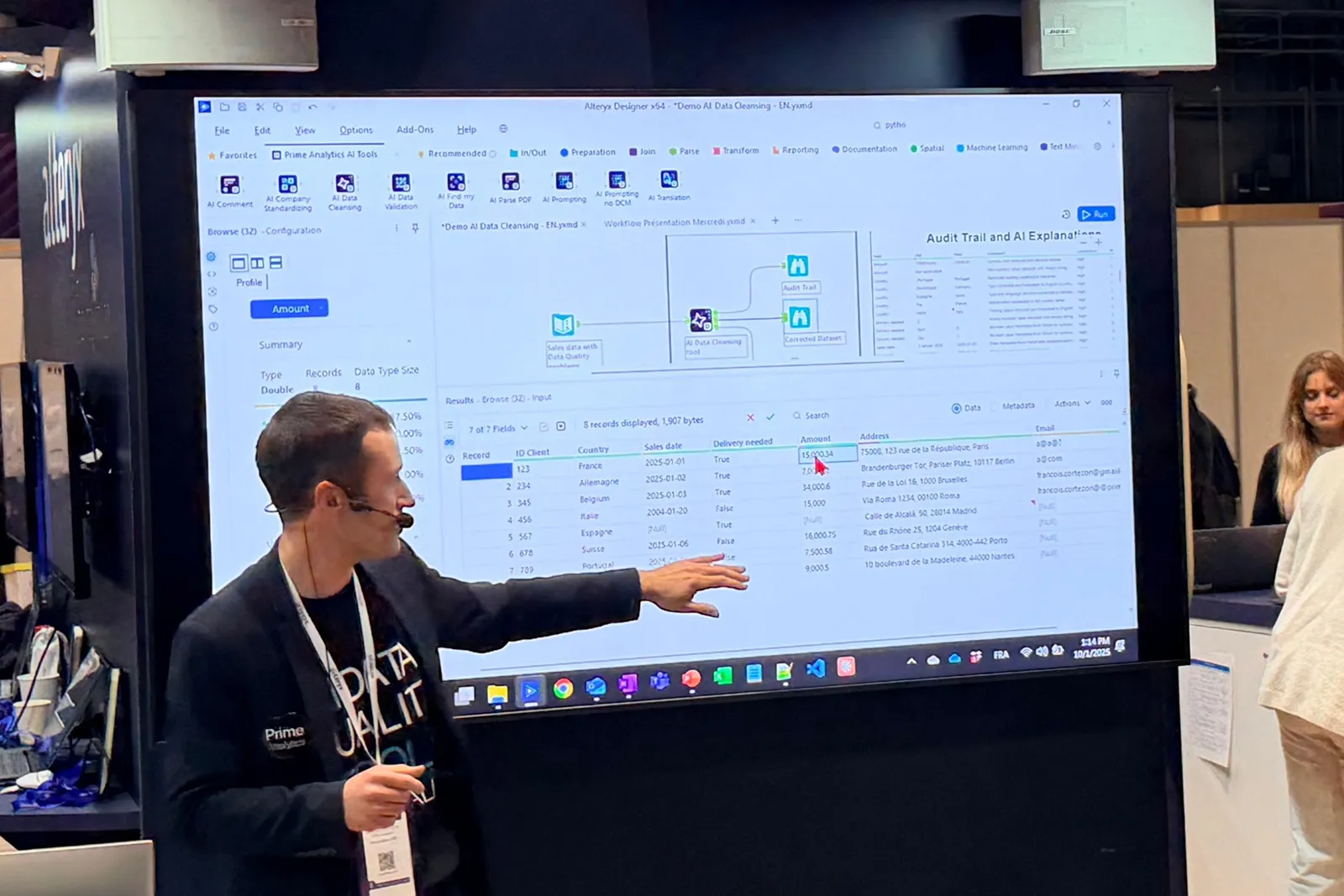
• Data Profiling — Le point de départ obligatoire
Expose pour chaque champ d’un dataset un ensemble complet de statistiques — count, count_distinct_value, count_null_value, pct_missing, avg_value, min/max, percentiles (5, 25, 50, 75, 95). Premier réflexe quand un dataset arrive dans votre pipeline. En 2 minutes, vous voyez si un champ est vide à 40 %, si les valeurs numériques ont des outliers, si les distributions correspondent à ce que vous attendiez.
Piège à éviter : ne jamais négliger cette étape. Nous avons vu des projets partir sur des dashboards, découvrir 3 mois plus tard qu’un champ critique était vide à 60 %.
• Completeness Check — La conformité automatisée
Vérifie que le taux de complétude de chaque champ dépasse un seuil minimum défini dans un fichier de configuration (par exemple 0,8 pour 80 %). Idéal pour les contrôles automatisés dans une chaîne de reporting réglementaire. Configurez finement par champ, par entité, par période.
• Uniqueness Check — Débusquer les doublons
Détecte les doublons et calcule les occurrences par valeur. Clé simple ou composite. Sur une base de 900 000 clients d’une grande banque française, il n’est pas rare de trouver 15 000 à 30 000 doublons.
Piège à éviter : commencer par des clés composites, pas par un email seul.
• Data Validation — Vos règles métier appliquées automatiquement
Valide chaque enregistrement contre des règles configurables (regex, min, max, listes autorisées). Résultat pass/fail par règle. Exemple bancaire : « IBAN au format ISO 13616 », « montant positif », « code produit dans la liste autorisée ». Documentez les règles dans un fichier partagé, pas dans le workflow.
• Fields Checks & Fields & Types Checks — La conformité structurelle
Vérifient que la structure du dataset correspond au modèle de données attendu, et convertissent automatiquement les types si nécessaire. Idéal avant intégration d’une source externe.
• Reference Validation — L’alignement aux référentiels
Vérifie que les valeurs sont conformes à des listes de référence autorisées (codes pays ISO, codes statut, référentiels internes). Matérialiser un cadre MDM sans passer par un outil MDM lourd.
Piège à éviter : maintenir vos référentiels hors du workflow (fichier partagé, base référentielle, API externe).

5. Le pipeline type : comment articuler ces outils
Étape 1 — Explorer avec Data Profiling. Comprendre la structure et les anomalies avant tout.
Étape 2 — Contrôler la structure avec Completeness Check, Uniqueness Check, Fields Checks, Fields & Types Checks.
Étape 3 — Valider métier avec Data Validation (règles configurables) et Reference Validation (référentiels autorisés).
Étape 4 — Enrichir par IA avec AI Prompting et AI Comment. Uniquement où l’IA apporte une valeur incrémentale.
Étape 5 — Restituer via des dashboards Power BI ou Tableau alimentés directement depuis Alteryx, avec audit trail complet.
Chaque étape est indépendante et composable.
6. Notre philosophie : quatre principes non-négociables
🔌 Plug-and-play. Installation native dans Alteryx Designer & Server. Pas de nouvel outil, pas d’infrastructure supplémentaire, pas de surcoût.
🛡️ Souverain par construction. Aucune donnée n’est envoyée à l’extérieur de votre environnement. Vous restez maître de votre LLM, de votre infrastructure et de votre cadre de gouvernance.
🔀 LLM-agnostique. Nos outils fonctionnent avec les LLMs de votre choix : Mistral, OpenAI, Claude, Gemini, modèles internes auto-hébergés.
🎓 Accompagnement disponible à la demande. Les outils sont conçus pour être utilisés en autonomie. Mais si vous voulez aller plus loin — adaptation à vos référentiels, intégration à vos pipelines, formation, déploiement à l’échelle — nos consultants prennent le relais.

7. Pourquoi nous avons choisi de rendre ces outils gratuits
Question légitime : si ces outils ont demandé plusieurs mois de développement, pourquoi les rendre gratuits ?
D’abord, parce que la Data Quality est un enjeu collectif. L’écosystème Alteryx francophone est riche mais fragmenté. Chaque équipe résout individuellement les mêmes problèmes. Mutualiser des outils robustes fait progresser tout le monde — y compris nos concurrents. Nous l’assumons.
Ensuite, parce que ces outils sont une porte d’entrée. Un CDO qui télécharge la bibliothèque, l’installe, la teste, découvre qu’elle marche — commence à nous connaître. Quand il aura un vrai chantier de transformation Data Quality, il pensera à nous.
Enfin, parce que notre métier n’est pas la vente d’outils. Notre métier, c’est le conseil, la régie, la formation. Les outils sont l’un des supports de notre expertise — pas notre produit principal.
Le “so what”
Si vous êtes utilisateur Alteryx en banque, en assurance ou en grande entreprise : téléchargez le pack, testez sur un ou deux cas d’usage internes, jugez sur pièces. Aucun engagement, aucun coût. Si ça vous convient, on en discute.
En conclusion, la qualité des données n’est pas un enjeu de contrôle. C’est un enjeu de vitesse.
Une donnée fiable permet de lancer un projet IA en 3 mois au lieu de 18. Elle permet d’itérer rapidement, de tester plusieurs approches, de scaler. À l’inverse, une donnée douteuse ralentit tout — chaque décision devient un débat, chaque anomalie une enquête, chaque livrable un compromis.
Nos outils AI Data Quality pour Alteryx sont conçus pour rendre cette qualité accessible, industrielle et durable — sans effort supplémentaire pour les équipes, sans dépendance à un éditeur, sans compromis sur la souveraineté.
Ils sont gratuits. Ils sont éprouvés dans des environnements bancaires exigeants. Ils sont conçus pour être compris et utilisés par des équipes métier — pas seulement par des Data Engineers.
Il ne vous reste plus qu’à les essayer.
Demandez votre pack complet et gratuit →


Nous vous recontacterons dans les plus brefs délais.
Veuillez réessayer ou nous contacter à l'adresse contact@primeanalytics.fr.